机器学习入门
posted on 11 Mar 2019 under category ML
前两天看到一篇系统介绍机器学习进阶学习的资料,感觉上面说到的步骤的可操作性还是比较强的,因此想以记笔记的方式来加强学习效果。
Chapter 1 鸟瞰思维
机器学习 ≠ 算法
机器学习并不是关于算法的,机器学习是关于问题解决的综合性方法,而单独的算法只是这个综合性问题的一小块,问题剩下的部分是关于如何正确的运用算法。
什么使得机器学习变得如此特殊?
机器学习就是教会电脑如何从数据中学习到特定的模式从而做出决策或者预测,对于真正的机器学习,电脑必须能够学习到无法用显示程序识别的模式。
例子:好奇的小孩
一小孩在家玩耍…当他看到一支燃烧的蜡烛的时候,他好奇的走过去。1.出于好奇,他把手伸向蜡烛的火焰。2.”哎哟!”他叫出声来,并迅速的缩回手。3.“嗯…那个红色的发光的东西原来是可以伤人的!”。两天以后,他在厨房玩耍…他看到厨房燃烧的炉子,他再次好奇的走过去。1.他是好奇心再次爆发,想着把手伸过去。2.突然,他意识到炉面是“红色的、发光的”。3.“啊!”他突然有所顿悟“今天可不能在这样了”。4.他回想起来了“红色的发光的东西会让人感到疼痛的”,然后他就离开了炉子。
非常明确,这里只包含机器学习,因为小孩从蜡烛里学习到了模式:
- 他学习到了“红色的发光的东西会让人感到疼痛的”
- 另一方面,如果他仅仅是因为父母的警告而离开炉子,那就是“显示程序”(explicit programming)而非机器学习了。
关键术语
- 模型(Model): 从数据中学习到的一系列模式
- 算法(Algorithm): 用来训练模型的特殊的机器学习方法
- 训练集(Training data): 算法用来训练模型的数据库
- 测试集(Test data): 用来评估模型的新数据库
- 特征值(Features): 数据库中用来训练模型的变量(列)
- 目标值(Target variable): 用于预测的特殊变量
- 观测值(Observations): 数据库中的数据点(排)
例子:小学生
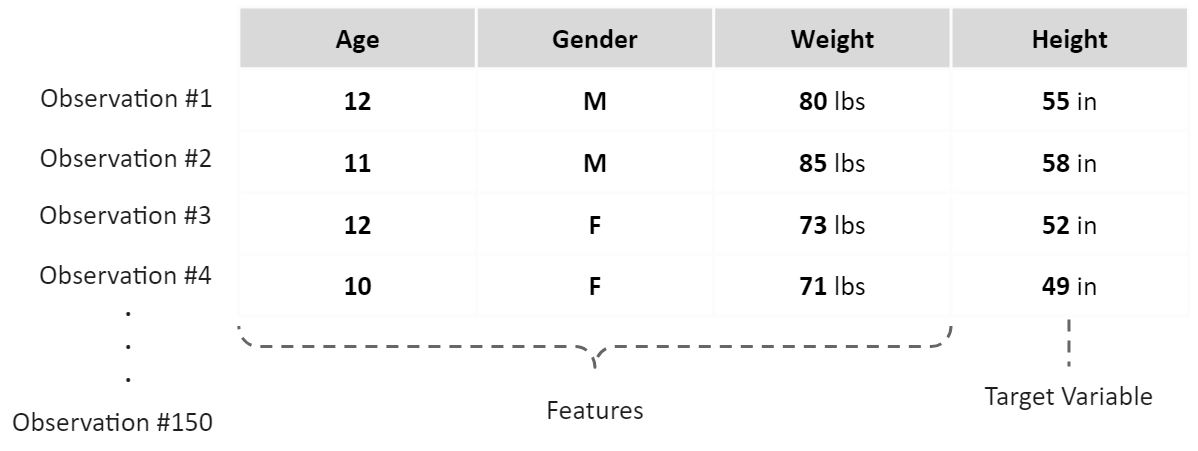
例如,你手上有一批150人的小学生信息数据库,并且你想用这些学生的年龄、性别和体重等来预测他们的身高
- 你有150个观测值
- 一个目标值(身高)
- 3个特征值(年龄、性别、体重)
- 你可以把你的数据分为两部分:1.其中的120人作为数据库来训练模型(训练集) 2.剩下的30人用来选择最佳模型(测试集)
机器学习的任务
学术界的机器学习专注于算法研究。然而,在实际应用中,你应该首先关注的机器学习的任务。
- 任务就是你的算法的特殊对象
- 只要任务明确了,算法是可以随时换动的
- 实际上,你应该经常尝试不同的算法,因为你并不知道哪一种算法和你的数据是最匹配的 在机器学习中,最常见的两种任务分类是:监督学习和非监督学习
监督学习(Supervised Learning)
监督学习是针对有“标签”的数据而言的,它具有以下特征:
- 经常被当作预测模型的高级形式
- 每一个观测值都有“确定的答案”
- 你需要建立一个预测模型,因为在训练的时候你必须告诉算法什么是“正确的”
- 回归 任务是针对连续目标变量进行建模的
- 分类 任务是针对分类目标变量进行建模的
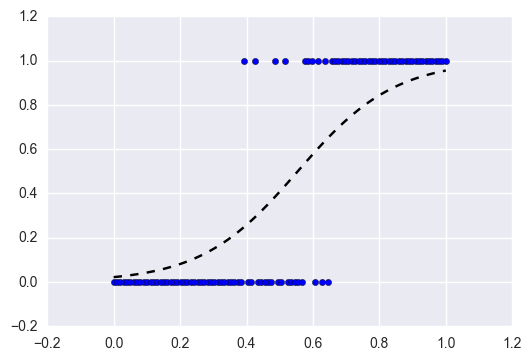
非监督学习(Unsupervised Learning)
非监督学习包含的任务是“无标签”数据(没有目标值),它具有如下特征:
- 在实际应用中,它经常被用作为自动数据分析或者自动的信号提取
- 无标签数据没有事先的“正确答案”
- 允许算法直接从数据中学习模式(‘不受监督’)
- 集群 是最常见的非监督学习任务,它用于在数据中区分组
机器学习的三要素
1.一位经验丰富的厨师(A skilled chef)
首先,尽管我们是“教电脑自身如何去学习”,但是人类的指导起着巨大的作用。
- 正如你所知道的那样,你需要不断的做出决择
- 实际上,第一个重要的决择就是如何指定一个能确保你的项目成功的路线图
2.新鲜的食材(Fresh ingredients)
第二个重要的因素就是数据本身的质量
- 垃圾的数据必然产生垃圾结果,不管你用哪种算法
- 专业的数据分析师一定是在理解数据、清洗数据和挖掘新特征上花最多的时间
3.避免烹调过度(Don’t overcook it)
机器学习中最危险的一个陷阱就是过度拟合。一个过度拟合的模型“记住”的是训练集中的噪音,而不是学习真正的潜在模式。
- 对冲基金中的过度拟合模型可以导致数百万美元的损失
- 医院中的过度拟合模型可能使成千上万人丧命
- 虽然在大多数的实际应用当中,过度拟合模型不会造成如此大的灾难,但是它仍然是你要竭力避免的严重错误
蓝图
机器学习的5大核心步骤:
- 1.探索分析(Exploratory Analysis) 首先,你必须要“理解”数据。这一步一定要快!快!快!!!
- 2.数据清洗(Data Cleaning) 其次,清洗你的数据可以避免很多常见的陷阱,好的数据胜过优秀的算法
- 3.特征提取(Feature Engineering) 再次,通过挖掘新的特征来帮助你的算法聚焦于什么是重要的
- 4.算法选择(Algorithm Selection) 在最短的时间里选择最优、最合适的算法
- 5.模型训练(Model Training) 最后,训练你的模型。只要你前面的4步完成了,这一步就很公式化了。
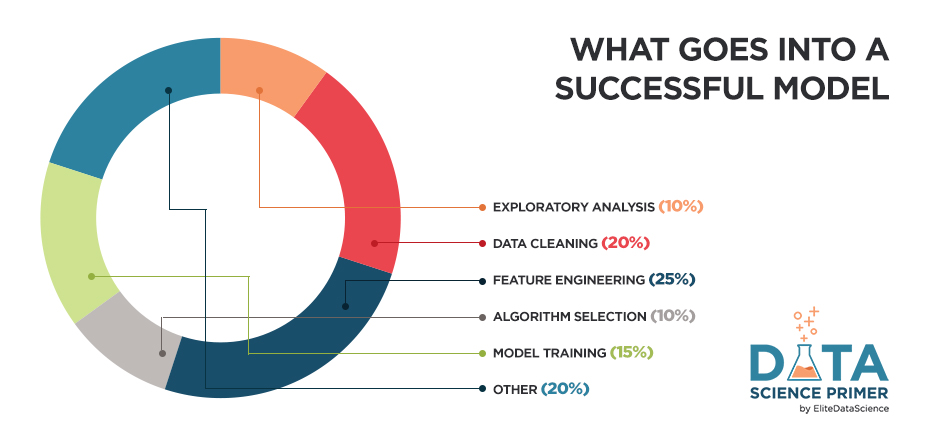
机器学习不应该是随机的、零碎的,而是系统的、有组织的。另外,即使你一点都不记得前面讲的内容,记住“好的数据比优秀的算法跟重要”。
补充阅读:
数据分析师应避免犯的9个错误https://elitedatascience.com/beginner-mistakes
给入门者的65+免费科学数据资源https://elitedatascience.com/data-science-resources
Python机器学习教程https://elitedatascience.com/python-machine-learning-tutorial-scikit-learn
Chapter 2 探索分析
为什么要提前探索数据集?
探索数据集的目的是“了解”这个数据集。提前探索数据集可以使接下来的步骤更顺畅,主要包括一下3个方面:
1.可以为数据清洗获取有价值的提示
2.可以为之后的特征提取寻找灵感
3.可以使你对数据有“感觉”,这将对之后的结果产出有重要的影响
然而,数据探索的步骤应该迅速、高效、果断…不要深陷! 不要跳过这一步,不过也不要陷入其中。
从最基础的开始
首先,你应该回答有关这个数据集的一些基本问题:
- 我拥有多少观测值?
- 有多少特征值?
- 我的特征值是什么样的数据类型?是数值型的还是分类型的?
- 有目标值吗?
画数据分布图
通常情况下,一个简单的 直方图 就足够理解数据的分布了,有以下事项需要特别注意:
- 意料之外的分布
- 潜在的不合理的异常值
- 特征值应该是二进制的
- 界线没有意义
- 潜在的测量误差
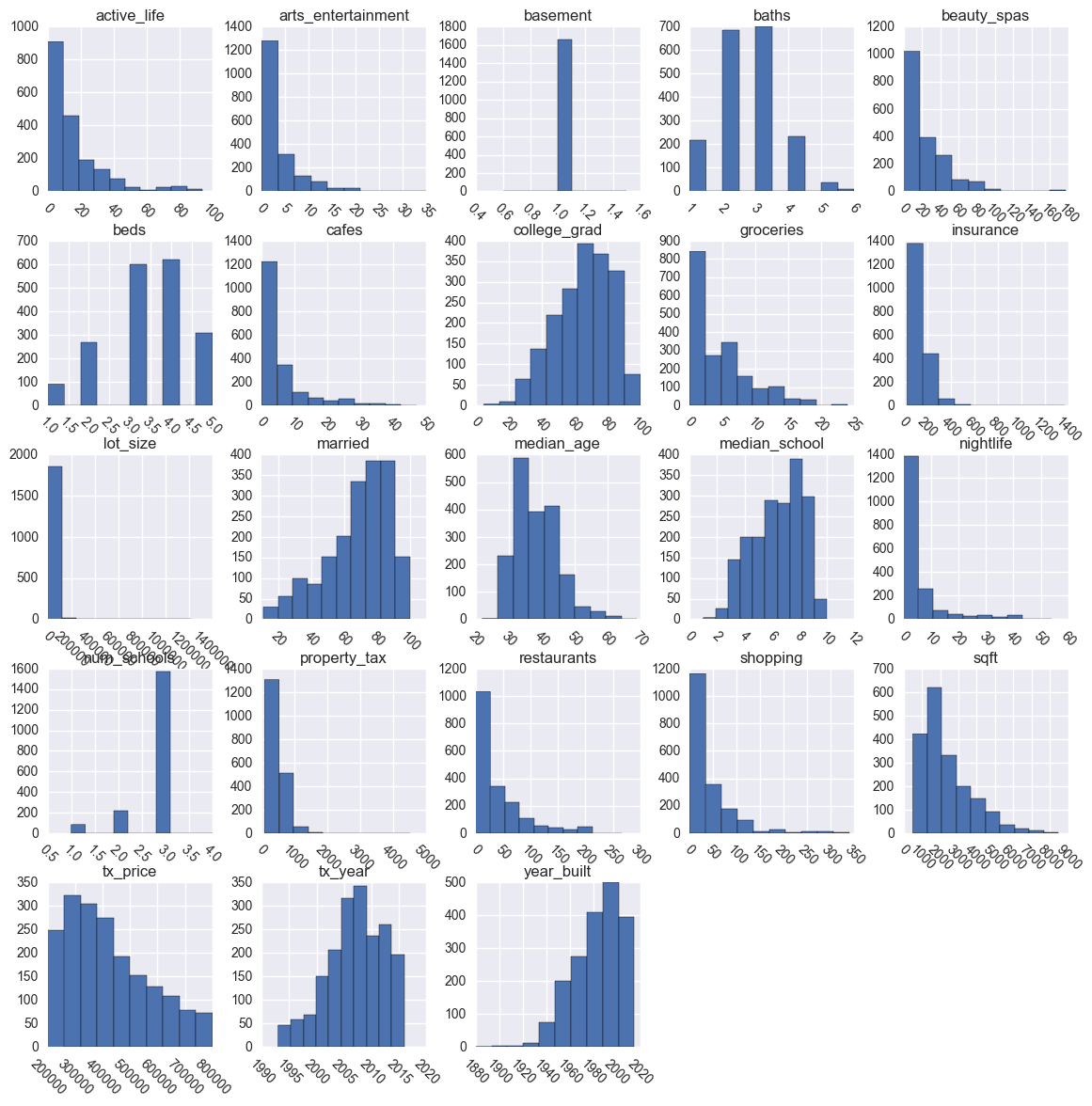
从现在开始,你应该开始记录你想要做出的修改。如果有些看起来不太合适的东西,比如特征值中有潜在的异常值,那么现在是告诉客户的好时机,或者进一步深度挖掘。
画分类分布图
分类型的数据就不能用直方图来展示,而要用条形图。特别的,你需要提防稀疏类,这种类具有很少的观测值。需要强调的是,“类”只是分类特征中的一种特定值。例如,下面的条形图展示的是被称为“exterior_walls”的特征值的分布,所以像 Wood Siding, Brick, 和 Stucco 就是这个特征值的每一个类。
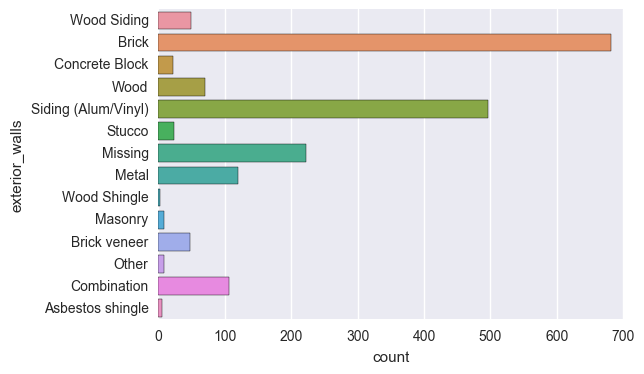
现在,我们再返回谈谈稀疏类…正如你看到的那样,“exterior_walls” 的一些类的条状的长度很短,它们就是稀疏类。它们会给建模的时候带来一些麻烦。
- 如果情况好的话,它们不会对模型造成多大的影响。
- 如果情况不好的话,它们将造成模型的过度拟合。
因此,我们建议在后面对这些类进行组合和重新分配的时候做下注释。我们一般会将这些注释一直保存到特征加工。
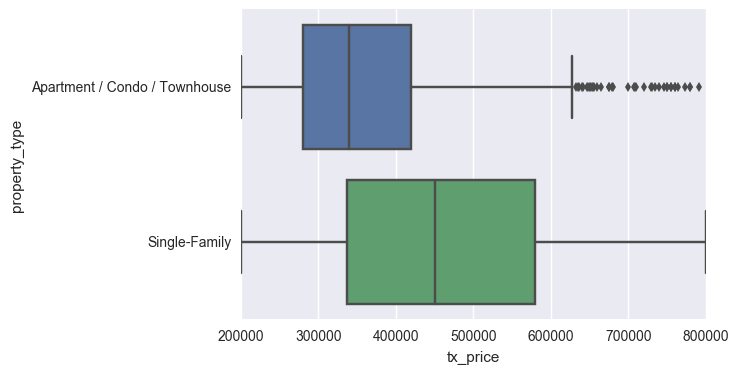
画分段图
画分段图是观察分类型特征值和数值型特征值之间关系的有效方法,箱形图可以帮你做到。以下是你可以从下图中得到的一些见解:
- 单户交易额的中间值远比公寓/别墅要高
- 两种类的最大和最小交易额是想当的
- 事实上,整数型最小值($200k)和最大值($800k)表明可能存在数据截断…
- 记住这个在之后评估你的模型通用性的时候非常重要
研究相关
最后,相关分析可以让你了解数据特征值和其它特征值之间的关系。相关是一个介于-1和1之间的值,它表示的是两个特征值在改变的过程中的紧密程度:
- 正相关表示的是一个特征值随着另一个特征值的增大而增大
- 负相关表示的是一个特征值随着另一个特征值的增大而减小
- 相关系数接近-1或者1表示两个变量之间具有很强的关系
- 相关系数接近0表示两个变量之间的关系很弱
- 相关系数为0表示两个变量之间没有关系
相关 热力图 可以让你的数据信息变得可视化
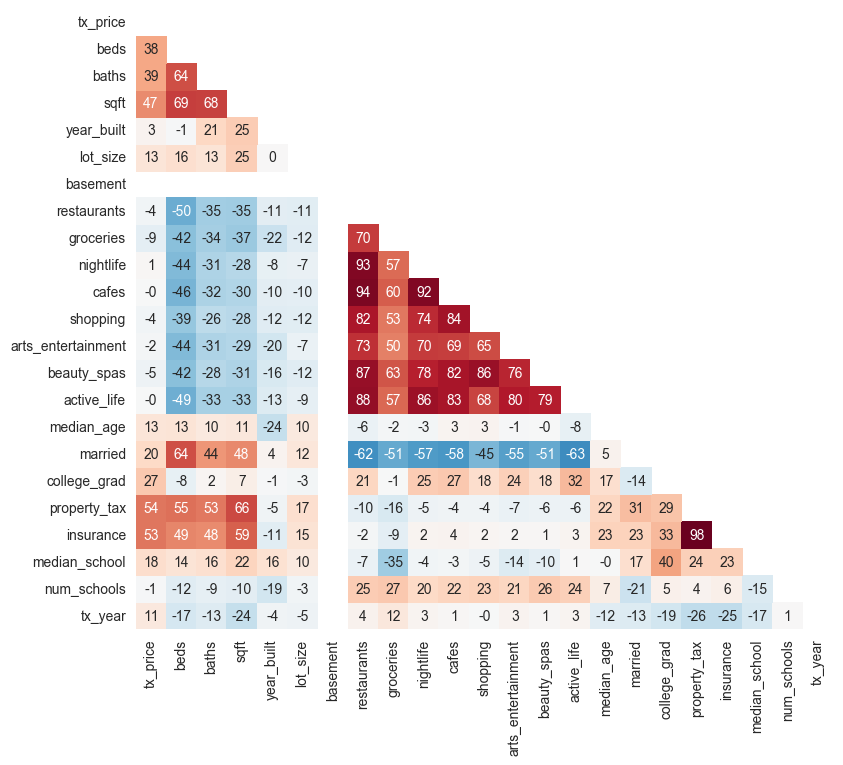 通常,你需要留意以下信息:
通常,你需要留意以下信息:
- 哪一个特征值与目标值具有较强的相关
- 对其它特征值之间的强相关感兴趣或者有所期待吗?
再次强调,你的目标是获取对数据的“感觉”,这可以让后面的工作更顺畅。
补充阅读:
使用Python进行数据的可视化https://elitedatascience.com/python-seaborn-tutorial
Chapter 3 数据清洗
好的数据 > 漂亮的算法
数据清洗是一项每个人都做过但是又没有人愿意讨论的工作。的确,在机器学习中甚至都不存在这个部分。但是合适的数据是决定你的项目生死存亡的关键。专业的数据分析师经常会在这块花大量的时间和精力。因为在机器学习领域有一个非常简单的法则:好的数据大于漂亮的算法。实际上,假如你拥有合适的干净的数据,那么即使非常简单的算法也能从数据中得到深刻的结论。很显然,不同类型的数据要求不同的清洗方法,本文所介绍的系统的方法可以作为一个很好的起点。
删除不想要的观测值(Remove unwanted observations)
数据清洗的第一步是从你的数据集中清除不想要的观测值,这其中包括重复的(duplicate)或者不相关(irrelevant)的观测值。
重复的观测值(Duplicate observations)
重复的观测值经常产生于数据收集过程中:
- 从多个地方合并数据集
- 获取数据(Scrape data)
- 接受客户或其他地方的数据
不相关的观测值(Irrelevant observations)
不相关的观测值是指那些与你要解决的问题不相适的数据。
-
例如,如果你想要建构一个单户住宅的模型,你并不希望出现公寓类型的观测值
-
同样,也是回过去查看你的探索性分析图表的绝佳时间。你可以查看分类特征的分布图,看看是否存在不应该存在的类。
-
在提取特征值之前检查不相关的观测值可以避免很多麻烦。
修复结构上的错误
数据清洗的下一步是修复结构上的错误,结构错误是指在测量过程中、数据传输或其它过程造成的“糟糕的管理(poor housekeeping)”。
例如,你可以检查拼写、大小写不一致等错误。主要是关注分类特征,你可以查看条形图。下面就是一个例子:
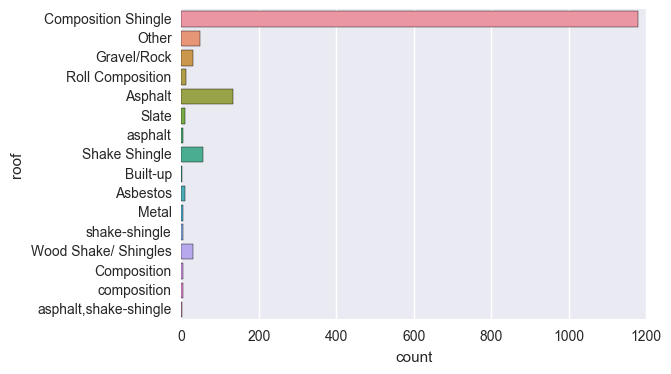
就像你看到的那样:
- ‘composition’ 和 ‘Composition’ 一样
- ‘asphalt’ 应该是 ‘Asphalt’
- ‘shake-shingle’ 应该是 ‘Shake Shingle’
- ‘asphalt,shake-shingle’ 应该是 ‘Shake Shingle’
当我们把拼写和大小错误解决之后,类的分布就变得干净了:
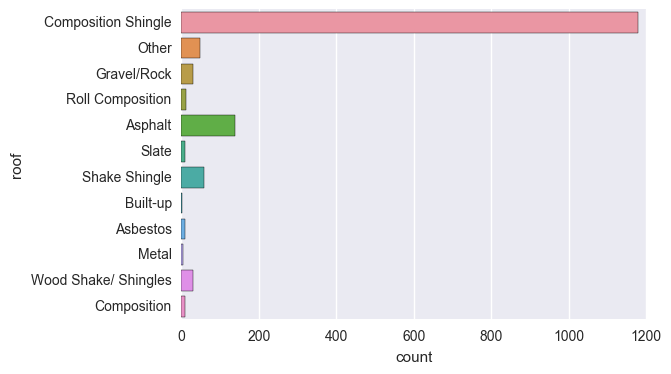
最后,检查一下标签错误的分类,例如分开的类可能是一样的:
- 例如,如果‘N/A’和‘Not Applicable’ 是作为两个类,你可以将它们合并在一起
- 例如,‘IT’和‘information_techology’应该是作为一个类
过滤掉不想要的异常值
异常值可能会给某些特定类型的模型带来问题。例如,线性回归模型对异常值的鲁棒性就不如决策树模型。总的来说,如果你有合理的理由删除异常值,那么对你的模型的优化很有帮助。
然而,当异常值被证明为“有罪”之前,它是“无辜的”。你不能仅仅是因为它是一个“大数”而就把它给删除掉,这个大数可能对于你的模型来说是一个非常关键的信息。
再次着重强调,你必须有足够的理由删除异常值!
处理缺失数据
在机器学习的应用中,缺失数据是一个非常棘手的问题。首先,需要明白的是,你不能简单的忽视你的数据集中的缺失值。你必须非常实际的解决这个问题,因为大部分的算法并不接受缺失值。
‘常识’在这里并不合理
不幸的是,根据我们的经验,处理丢失数据最常用的两种方法实际上是非常糟糕的。这两种方法分别是:
1.删除缺失的观测值
2.根据其它的观测值计算缺失值
删除缺失值的方法是欠佳的,因为当你删除观测值的时候,你就删除了信息。
- 实际上,缺失值本身就包含了信息
- 另外,在实际中,即使丢失了某些特征,你仍需对新的数据做出预测!
计算缺失值同样也是欠佳的,因为这个值本来是缺失的,但是你却把它填满,这样同样造成了信息缺失,不管你是用什么复杂的方法。
-
同样,‘缺失’本身是能提供信息的,如果某个值确实,你应该‘告诉’你的算法。
-
尽管你建立了一个模型来计算你的缺失值,你并没有增加任何真实的信息。你只是在强化其它特征已有的模式。
简而言之,你应该经常告诉你的算法,因为缺失值是有信息的。那么我们该如何做呢?
缺失的分类数据
解决分类数据缺失的最好办法就是简单的把它标为‘缺失’!
- 你实际上是为这个特征增加了一个新的类
- 这是告诉算法某个值缺失了
- 这个也解决了没有缺失值的技术需求
缺失的数字数据
对于缺失的数字类型的数据,你应该 标记 并 填充 这个缺失值。
1.用缺失值指标变量来标记观测值。
2.然后,用0来填充缺失值,以满足无缺失值的技术需求。
通过运用标记和填充技术,本质上是让算法寻找最优的缺失常数,而不是用平均值来填充。
进一步阅读资源:
如何解决机器学习中的非平衡类的问题 https://elitedatascience.com/imbalanced-classes
用于数据科学和机器学习的数据集 https://elitedatascience.com/datasets
Chapter 4 特征提取
在前面的章节中,我们已经学习了数据清洗的基本框架。我们修复了结构错误、处理了缺失数据并且过滤了观测值。本章中,我们将学到的是如何通过提取特征值来帮助我们的算法改善我们的模型。需要铭记的是:在所有的核心步骤中,数据分析师通常会在特征提取上花最多的时间。
什么是特征提取?
特征提取是指从已存在的特征中创造新的输入特征。通常来讲,你可以将数据清洗看作为减法,而将特征提取看作为加法。这通常是数据分析师能够为改善模型而做的最有意义的工作了,有以下三个理由:
1.你可以分离出,并强调关键的信息,这可以使你的算法能够‘集中注意’于最重要的地方。
2.你可获得专业知识。
3.最重要的是,一旦你理解了特征提取这个‘词汇’,你便可以给他人带来专业知识。
在这一节中,我们将介绍一些启发性的方法来帮助你激发新的想法。在继续之前,我们想要提醒的是,因为篇幅有限,这并不是特征提取的详细纲要。不过好消息就是,随着你拥有更多的经验,你的技能就自然而然的提升。
渗入专业知识
通常,你可以利用你或者其他人的专业知识来提取特征信息。试着想象一下你可能想要分离的独特信息,这里你有很多“创作自由”。再返回到房地产的数据集,假设你还记得住房危机发生在同一时间段。
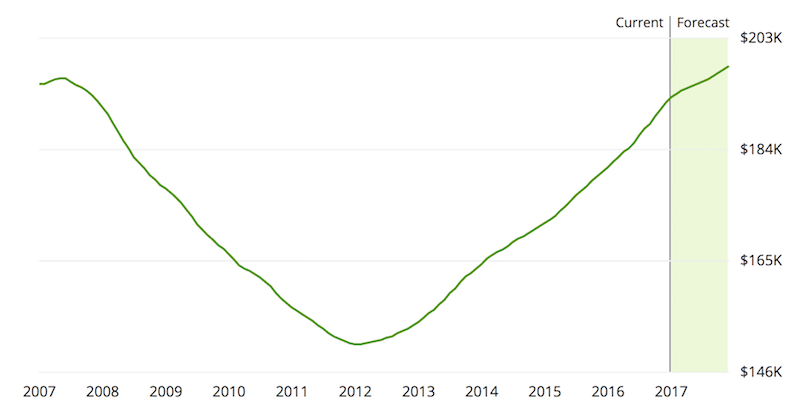
如果你怀疑房价会受到影响,你可以为这段时间的交易创造一个指标变量。指标变量是二进制变量,要么是0要么是1。它们‘指示’某一观测值是否满足某种条件,并对分离关键属性非常有用。如你怀疑的那样,‘专业知识’是非常广泛和开放的。在某种程度上,你会耗竭自己的想法从而陷入困境。那么接下来的步骤可以帮你激发一些灵感。
创造交互特征(Creat Interaction Features)
第一个试探是检查一下是否可以创造一些有意义的交互特征,它们可以是合并两个或者更多的特征。顺便提一下,在一些情境中,‘交互项目’必须是两个变量之间的乘积。在我们的情景中,交互特征可以是两个变量之间的乘积、总和或者差值。一般的技巧是查看每一对特征并问自己“我可以以更加有效的方式合并这些信息吗?”
案例(房地产)
- 假设我们已经有了一个名为‘num_schools’的特征,即距离某个属性5英里以内的学校数量。
- 假设我们还有一个名为‘median_school’的特征,即那些学校质量得分的中位数。
- 然而,我们可能会有一些疑问:真正重要的是有许多学校可供选择的前提是这些学校必须都是很好的学校。
- 为了计算交互作用,我们可以简单的创造一个新的特征 ‘school_score’ = ‘num_schools’ x ‘median_school’
合并稀疏类(Combine Sparse Classes)
下一个可以给我们启发的方法是归类稀疏类。
稀疏类 (在分类特征中)有很少的观测值。它们可能给某些机器学习的算法带来问题,并导致模型过拟合。
- 没有绝对的标准说每一个类需要包含多少观测值
- 这个同样取决于你的数据集的大小以及其他特征的数量
- 根据经验,我们建议合并一些类直到观测值大于50
我们以房产为例:
首先,我们可以归类相似的类。在上面的图表中,’exterior_walls’这个特征有几个类是相似的。
- 我们可以将‘Wood Siding’,‘Wood Shingle’ 和 ‘Wood’ 归为一个单一的类。实际上,我们可以将它们标记为‘Wood’。
接下来,我们可以将剩下的稀疏类都归为‘Other’这一类。
- 我们将‘Concrete Block’,‘Stucco’,’Masonry’,’Other’ 和 ‘Asbestos shingle’ 统一归为‘Other’。
下面使我们重新归类后的图表:
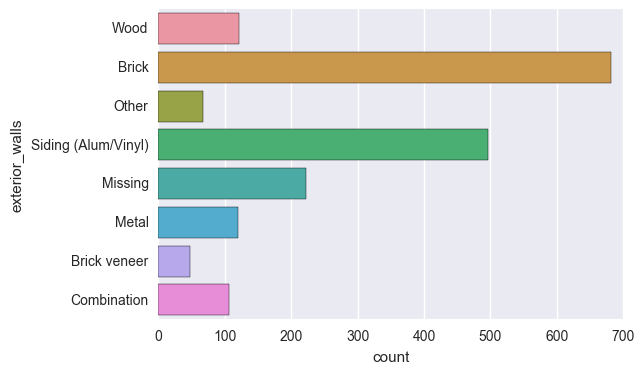
合并稀疏类之后,单独的类就很少了,但是每一个类都有更多的观测值了。通常情况下,通过目测就能够判定是否把某些类归为一起。
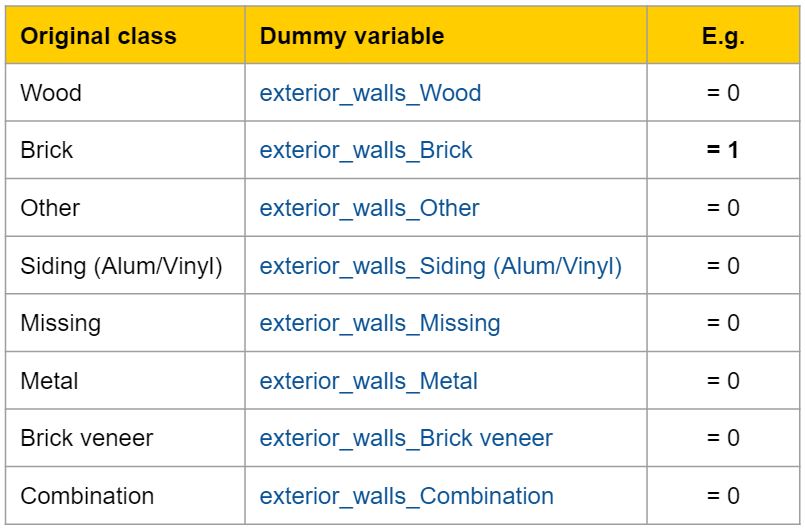
添加虚拟变量
大多数的机器学习算法无法直接处理分类特征,尤其不能处理文本值。因此,我们需要为分类特征创造一个虚拟变量。
虚拟变量 是一个二进制变量的集合,每一个变量都代表了一个分类特征的单类。
你所描绘的信息是一样的,但是用数字来代替文本可以通过算法的技术要求。在上面的例子中,对稀疏类进行归类之后,剩下的8个类可以转换成8种虚拟的变量:
删除无用的特征
从数据集中删除无用的和多余的特征。
无用的 特征是指那些没有意义的,没法传送到我们机器学习算法中的特征。包括:
- ID栏
- 这些特征在预测中是用不上的
- 其它的文本描述
多余的 特征是指那些在特征提取过程中被其他特征替换掉的特征。
进一步阅读:
特征提取最好的练习材料 https://elitedatascience.com/feature-engineering-best-practices
Chapter 5 算法选择
如何选择机器学习的算法
在本节中,我们将介绍5种对于回归任务非常有效的算法,每一种算法都有对应的分类。我们没有列出一长串算法,而是尽量教你导致一些算法优于其他算法的一些非常重要的概念(例如正则化、集成,自动特征选择)。在机器学习的应用中,应该是根据哪种算法适合问题和数据集来决定该算法的去留。因此,我们应该关注直觉和实际效益而不是数学和理论。
为什么线性回归是有缺陷的?
为了引入一些高级算法的推理,我们从讨论基础的线性回归开始。线性回归应用得非常普遍,但是它有很大的缺陷。
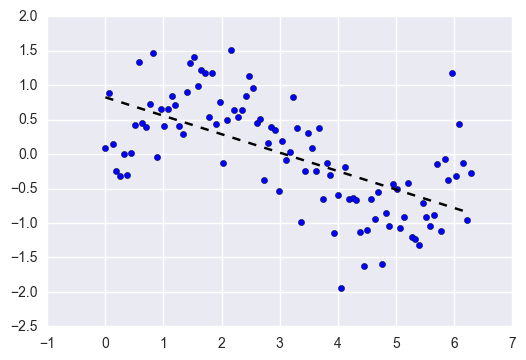
简单的线性回归模型被拟合为一条直线,在实际应用中,它们很少有派上用场的,因此大多数机器学习的问题可以考虑跳过它们。它们最大的优点就是比较容易预测和理解。但是,我们的目标并非研究数据以及写研究报告,我们的目标是建立一个能够精确预测的模型。
在这一方面,简单的线性回归有两大缺陷:
1.很可能对输入的特征过度拟合。
2.无法简单的表达非线性的关系。
让我们看看如何解决第一个缺陷。
机器学习中的正则化
这是改善模型的第一个‘高级’策略。在很多的机器学习的课程当中,它被视为高级的,但是它却非常容易理解和应用。线性回归的第一个缺陷就是很容易对输入的很多特征产生过度拟合。下面,我们举一些极端的例子来解释为什么会发生这种情况。
- 假如你的训练集中有100个观测值
- 假如你同样有100个特征值
- 如果你用一个线性回归模型来拟合所有的100个特征值,你能够很完美的‘记住’这个训练集
- 每一个系数仅仅是‘记住’一个观测值。这个模型可能对于训练集来说是非常精确的,但是对于未知数据来说却非常糟糕。
- 它并没有真正的学习到潜在模式,而仅仅是记住了训练数据中的噪音
正则化 是一项通过人为惩罚模型来防止过度拟合的技术。
- 它能够抑制较大的系数
- 它同样能够删除整个特征值(把系数设置为0)
- 惩罚的‘力度’是可以调整的
正则回归算法
有3种比较常见的正则线性回归算法:
Lasso 回归
Lasso代表的是最小绝对收敛和选择操作符。
- Lasso回归对系数的绝对大小进行了惩罚
- 实际中,可能导致系数恰好为0
- 因此,Lasso提供了自动特征选择,因为它能完全的删除一些特征
- 记住,惩罚的‘力度’应该调整
- 更强的惩罚会将更多的系数变为0
岭回归(Ridge Regression)
- 岭回归惩罚了系数的平方
- 在实际应用中,这将导致系数变小,但是不会让系数变为0
- 换言之,Ridge提供了特征收敛
- 再次强调,惩罚的‘力度’是可以调整的
- 一个更强的惩罚将导致系数更接近于0
弹性网络(Elastic-Net)
弹性网络是Lasso和Ridge之间的折中
- 弹性网络惩罚了绝对尺寸和平方尺寸的混合
- 两种惩罚类型的比率应该加以调整
- 整体强度也应该加以调整
如果你想知道,没有‘最佳’类型的惩罚,这取决于数据集和问题,我们建议尝试不同的算法,这些算法使得一系列的惩罚强度作为调优过程的一部分,我们将在下一章详细介绍。
决策树算法(Decision Tree Algos)
我们刚刚看到了3种算法可以防止线性回归过度拟合。但如果你还记得,线性回归有两个主要缺陷:
1.很容易对输入的特征过度拟合
2.不太容易表达非线性关系
那么,我们如果解决第二个缺陷呢?
好吧,我们需要远离线性回归模型…我们需要引入新的分类算法。决策树将数据建模为分层分支的‘树’。它们不断的制造分支直到代表预测的‘叶子’。
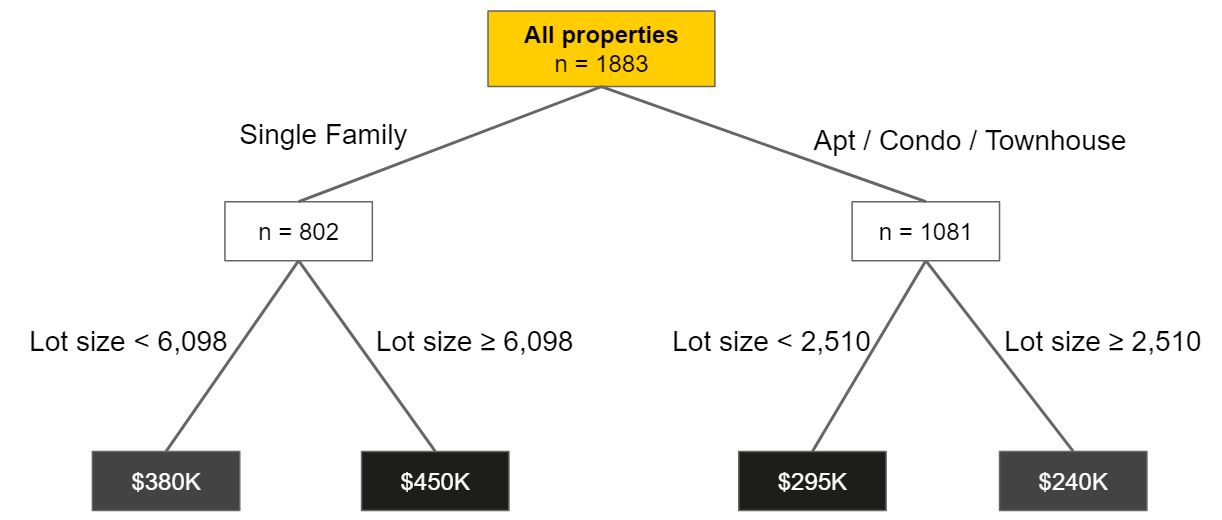
由于它们具有的分支结构,决策树很容易模拟非线性关系。
- 例如,假如是单住宅,一大块地才需要较高的价格
- 然而,假如是公寓,一小块地就需要较高的价格
- 除非你显示地添加交互项,否则线性模型很难捕捉这种相关性的反转
- 另一方面,决策树可以自然的捕获这些关系
不幸的是,决策树同样也遭遇了很大的缺陷。如果让它们无限的增长,它们就可以通过创建越来越多的分支完全的‘记住’训练数据。这样的话,单个不受约束的决策树就很容易过度拟合。所以,我们该如何利用决策树的灵活性,同时防止过度拟合呢?
树的集成
集成是从多个独立的模型中的预测值组合在一起的机器学习算法。集成有很多不同的方法,但是最常见的是以下两种:
Bagging
Bagging试图减少过度拟合复杂模型的机会。
- 它同时训练了大量‘强’的学习者
- 一个强学习者是一个相对不受约束的模型
- 接着,Bagging将所有的强的学习者给合并起来,以平滑它们的预测值
Boosting
Boosting试图改善简单模型的预测灵活性。
- 它训练一系列的‘弱’的学习者
- 弱学习者是一个受约束的模型(即可以限制每个决策树的最大深度)。
- 系列中的每一个值都着重于从前一个错误中学习
- 接着,Boosting就将这些弱的学习者合并为一个单一的强学习者
虽然 bagging 和 boosting 都是集成方法,但它们是从相反的方向解决问题。Bagging使用复杂的基本模型并试图‘平滑’他们的预测值,而boosting使用简单的基本模型并试图‘提高’他们的总体复杂性。集成是一个通用术语,但当基本模型是决策树时,它们有特殊的名称:随机森林(random forests)和增强树(boosted trees)
随机森林
随机森林训练的是大量的‘强’的决策树并通过bagging来合并它们的预测值。此外,随机森林的‘随机性’有两个来源:
1.每颗树只允许从要分割的特征的随机子集中进行选择(导致特征选择)
2.每棵树只接受随机观察子集的训练(此过程称为重采样)。
在实际应用中,随机森林往往表现得很好。
- 它们往往能击败其它需要数周才能开发出的模型
- 它们是非常完美的‘瑞士军刀’算法,几乎总能得到很好的结果
- 它们没有很多复杂的参数需要调整
增强树
增强树训练一系列‘弱的’、受限的决策树,并通过增强将它们的预测组合起来。
- 每棵树都允许有一个最大的深度,对此进行调优
- 序列中的每棵树都试图纠正前一棵树的预测错误
在实际应用中,增强树往往具有最高的性能上限
- 在经过适当的调优之后,它们往往能够击败许多其它类型的模型
- 它们在调优上比随机森林更复杂
进一步阅读:
现代机器学习算法:优势与劣势 https://elitedatascience.com/machine-learning-algorithms
降维算法:优势与劣势 https://elitedatascience.com/dimensionality-reduction-algorithms
机器学习中算法偏差的平衡 https://elitedatascience.com/bias-variance-tradeoff
Chapter 6 模型训练
如何训练机器学习的模型
终于,是时候训练我们的模型了!我们似乎花了一段时间才来到这一步,但是专业的数据分析师通常需要花大量时间在通往这一步的过程中:
1.探索数据
2.数据清洗
3.提取特征
再次强调:好的数据比漂亮的算法更重要。在这一章中,我你将学到如何建立模型以最大化的优化性能,同时防止过度拟合。我们会交换算法,自动的找到最佳参数。
分离数据集
让我们从一项非常重要但又很容易忽视的问题开始:支出你的数据。
将你的数据想象为有限的资源
- 你可以将你的数据一部分花在训练你的模型上
- 把另一部分花在评估你的模型上
- 但是,你不能将同一数据重复使用
如果你用训练模型时使用的数据来评估你的模型,你的模型很可能会过拟合,并且你很可能毫无发觉。一个模型的评估应该是针对新的、未知的数据。
因此,你应该将你的数据分为训练集和测试集集。
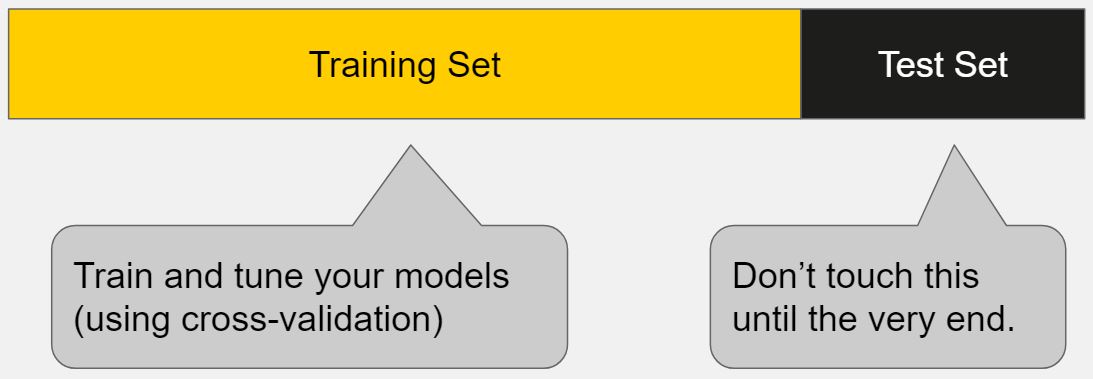
训练集是用来拟合、调整你的模型。测试集是被放在一边作为未知数据用来评估你的模型。
- 你应该总是将分离数据放在其它一切工作之前
- 这应该是获得模型性能的可靠性评估的最好方式
- 对数据分离完之后,不要碰你的测试集,直到你已经准备好选择你的最终模型
比较测试集和训练集能够避免过拟合…如果数据在训练集上的模型性能表现很好,但在测试集上表现得很差,那么很可能过度拟合。
什么是超参数(What are Hyperparameters?)
之前,我们已经多次提及‘调优’模型,现在是时候该正式看待这个主题了。当讨论调优模型的时候,我们特指调优超参数。在机器学习的算法中存在两类参数。最关键的差别在于模型参数可以直接从训练数据中学习到,而超参数却不能。
模型参数(Model parameters)
模型参数是定义单个模型的学习属性。
- 例如,回归系数
- 例如,决策树分类位置
- 它们能够从训练数据中直接学习到
超参数(Hyperparameters)
超参数表达算法的‘高级’结构设置
- 例如,在正则回归中用到的惩罚强度
- 例如,随机森林中包含的树的数量
- 它们是在拟合模型之前设定的,因为它们无法从数据中学习到
什么是交叉验证(Cross-Validation)
接下来,是时候介绍可以帮助我们调优模型的概念:交叉验证。检查验证是一种仅仅依靠你的训练数据来获得模型性能的可靠性评估的方法。交叉验证有多种方法,其中最常见的是:10倍交叉验证,它将训练数据分为10个相等的部分(也称为折叠),本质上是创建10个微型的训练/测试分隔。
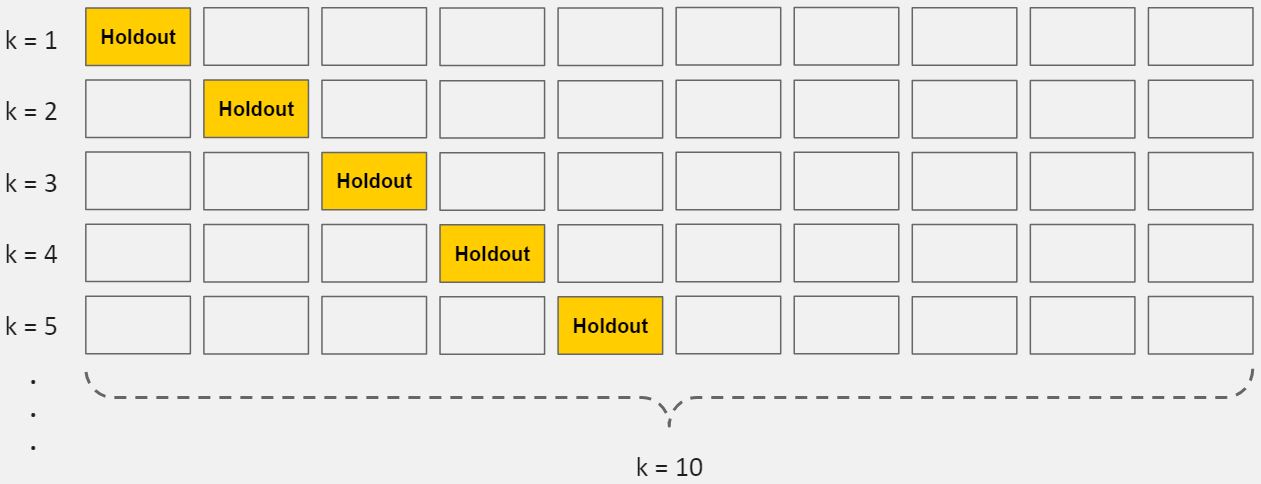
下面是10倍交叉验证的步骤:
1.将你的数据分为10个部分(层)
2.用9层(前9层)训练你的模型
3.用保留的1层评估
4.执行步骤(2)和步骤(3)10次,每一次保留不同的层
5.对10个保留层的性能进行平均
这10个保留层的平均性能就是你最终的性能评估,也称为交叉验证的得分。因为你创造了10个微型的训练/测试集,所以这个得分通常是非常稳定的。
拟合和调优模型
既然我们已经将我们的数据分成了训练集和测试集,并且学习了超参数以及交叉验证,那么该准备拟合和调优我们的模型了。基本上,我们需要做的就是对我们想要尝试的每一个超参数值集执行上述详细描述的交叉验证循环。高级伪代码如下:
For each algorithm (i.e. regularized regression, random forest, etc.):
For each set of hyperparameter values to try:
Perform cross-validation using the training set.
Calculate cross-validated score.
这一步完成之后,你会获得每一个超参数值的数据集、每一种算法的交叉验证分数。例如:
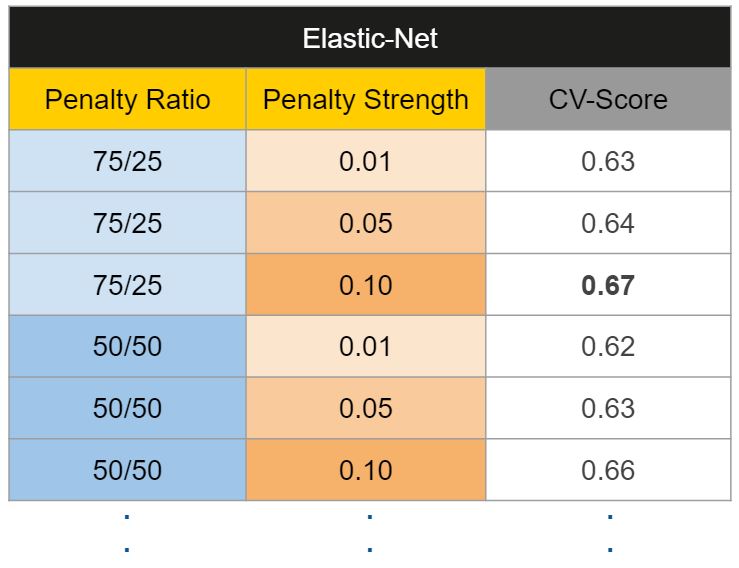
接着,我们将在每种算法中挑选最优的超参数集合:
For each algorithm:
Keep the set of hyperparameter values with best cross-validated score.
Re-train the algorithm on the entire training set (without cross-validation).
这有点像饥饿游戏,每种算法将它的’最优性能’送去作最终的选择,接下来…
选择胜出的模型
现在,通过交叉验证的调优,每种算法有了一个最优模型。最重要的是,到目前为止,你仅仅只是用了训练数据。现在,是时候评估每种模型并选择最优的一个,就像饥饿游戏的模式一样。因为你已经将你的测试集保存为真正的未知数据,现在你可以用它来评估每个模型性能的可靠性了。有许多的性能矩阵可供选择,我们是不会在这上面花太多的时间,但是通常情况下:
- 对于回归任务,我们推荐均方根误差(MSE)或平均绝对误差(MAE)。(数值越低越好)
- 对于分类任务,我们推荐ROC曲线下面积(Area Under ROC Curve,AUROC)。(数值越大越好)
过程非常简单:
1.用每一个模型对你的测试集做下预测。
2.使用这些预测值和测试集中的’基本事实’目标变量计算性能指标。
最后,根据一下问题来帮你选择胜出的模型:
- 哪个模型在测试集上的性能最好?(性能)
- 这个模型在其它不同的性能变量上的表现都很好吗?(鲁棒性)
- 该模型是否在训练集中也有最佳的交叉验证得分?(一致性)
- 这个模型解决了最初提出的商业性问题吗?(决胜条件)
进一步阅读:
机器学习中的过拟合:什么是过拟合?如何防止? https://elitedatascience.com/overfitting-in-machine-learning
如何解决机器学习中的非平衡类的问题 https://elitedatascience.com/imbalanced-classes
机器学习迭代的5个层次 https://elitedatascience.com/machine-learning-iteration
对于机器学习入门者有趣的项目 https://elitedatascience.com/machine-learning-projects-for-beginners
Chapter 7 接下来要做的
我们已经覆盖了很多领域:
1.在第一章中,你对机器学习的流程有了大概的了解
2.在第二章中,你学习到了快速的、高效的、果断的探索性分析方法
3.在第三章中,你学习了非常重要的数据清洗
4.在第四章中,你学习到了特征提取的技巧
5.在第五章中,我们讨论了正则化和集成,你学习了5种利用这种机制的算法
6.在第六章中,我们介绍了一个已被验证的公式,在其它步骤完成矫正之后,用来训练最佳模型
在这一章中,我们将指导你后面需要做的事情,包括如何将这些概念转化为对你职业有益的实用技能。
你有两个选择
选择一
第一个方法是独立去做,把这些技术运用到你感兴趣的项目中去。你学到的一步步的蓝图只是一个开端。要趁热打铁!选择一个数据集,然后开始练习。对于工具,我们强烈建议 Python 堆栈,包括以下库:
- NumPy 用于高效的数字计算
- Pandas 用于数据管理
- Scikit-Learn 用于算法和模型训练
- Seaborn 用于方便/常见可视化
- Matplotlib 用于定制可视化
当你掌握了核心的技术流程之后,你可以使用本教程的其他部分作为继续学习的指南。我们对于自学的同学的建议就是跳过课本,尽快的进入到项目中去,因为在具体情境中可以更快的学习。‘在做中学’
选择二
第二方法就是站在巨人的肩膀上。报名培训课程
(完结)